Qualitative Comparative Analysis (QCA) is often depicted as both a research approach and a data analysis technique. Transparency issues that arise during the QCA-as-an-approach phase of research - e.g. the collection of data, the construction and selection of cases, and the specification of the universe of cases - seem similar to issues in non-QCA qualitative research. What is unique to QCA is the computer-based analysis of a truth table. During this phase of research, transparency seems to be a feasible. We would therefore like to solicit your thoughts on this. We pose the following questions in order to get the debate started and to structure the discussion. Feel free to ask (and answer) additional questions, though.
a) Which, if any, problems do you see in being analytically transparent, i.e. which parts of the analysis of a truth table are potentially difficult to render transparent?
b) Which transparency criteria need to apply to the choice of conditions, their calibration, and the choice of cases?
III.4. Algorithmic analytic approaches
Forum rules
We encourage contributors to the Discussion Board to publicly identify by registering and logging in prior to posting. However, if you prefer, you may post anonymously (i.e. without having your post be attributed to you) by posting without logging in. Anonymous posts will display only after a delay to allow for administrator review. Contributors agree to the QTD Terms of Use.
Instructions
To participate, you may either post a contribution to an existing discussion by selecting the thread for that topic (and then click on "Post Reply") or start a new thread by clicking on "New Topic" below.
For instructions on how to follow a discussion thread by email, click here.
-
Carsten Schneider
Central European University - Posts: 4
- Joined: Fri Apr 08, 2016 3:40 am
-
Patrick Mello
Bavarian School of Public Policy, Technical University of Munich - Posts: 1
- Joined: Thu Oct 13, 2016 4:39 am
Re: QCA-related issues
In my view, principles of transparency are quite similar for QCA than for other non-QCA approaches. This means that (a) the choice of conditions/variables needs to be justified theoretically, (b) alternative explanations should be discussed, at least briefly, (c) and case selection criteria must be made explicit, especially when scope conditions lead to the exclusion of certain cases. It is important to realize that decisions in these threes area are often more consequential for one's QCA results than decisions made on the technical level.
In addition to research design issues, the technical/software-based side of QCA demands transparency regarding the exact steps of a researcher's analytical procedure. This entails (a) an explanation of how conditions were calibrated (raw data, calibration thresholds, function used, etc.) and (b) a full description of the truth table analysis and the computation of solution terms. Here, transparency should entail the discussion/documentation of alternative analyses (different calibration thresholds, analytical decisions, etc.).
Since R is on its way to become the new standard for QCA applications, researchers can easily provide transparency by making their R scripts available for published studies (via online appendices, journal repositories, etc.).
It's my impression that QCA has come a long way in terms of transparency through recent innovations. This means that the tools are all there - they just need to be used (and documented).
In addition to research design issues, the technical/software-based side of QCA demands transparency regarding the exact steps of a researcher's analytical procedure. This entails (a) an explanation of how conditions were calibrated (raw data, calibration thresholds, function used, etc.) and (b) a full description of the truth table analysis and the computation of solution terms. Here, transparency should entail the discussion/documentation of alternative analyses (different calibration thresholds, analytical decisions, etc.).
Since R is on its way to become the new standard for QCA applications, researchers can easily provide transparency by making their R scripts available for published studies (via online appendices, journal repositories, etc.).
It's my impression that QCA has come a long way in terms of transparency through recent innovations. This means that the tools are all there - they just need to be used (and documented).
Post Reply
-
Ingo Rohlfing
Cologne Center for Comparative Politics, Universität zu Köln - Posts: 20
- Joined: Tue May 24, 2016 5:45 am
Re: QCA-related issues
A truth table analysis and a statistical analysis are based on different (ontological and epistemological) premises, but they are implemented with software in a more or less standardized way. In general, the transparency requirements for a truth table analysis are the same as for quantitative research and Patrick points to some issues. R certainly makes it easier to be transparent by posting the data and script online. Teaching QCA and truth table analyses therefore should not only include teaching the technical skills, but the idea and standards of open science.
Post Reply
-
Alrik Thiem
University of Geneva - Posts: 6
- Joined: Fri Oct 21, 2016 7:50 am
Re: QCA-related issues
While I am absolutely sympathetic to the idea of increasing transparency, I believe the perspective that has been taken so far is too narrowly focused on applied users of Configurational Comparative Methods (CCMs) / Set-Theoretic Methods. Rather, at least five different groups of actors should be considered: (1) those who develop the software for CCM research, (2) those who use this software, (3) those who teach CCMs (4) journal editors/reviewers of CCM research and (5) publishers of CCM research. Without due attention to the role of each of these five different groups of actors in the research and publishing process, any comprehensive attempt at increasing research transparency to a reasonable standard is unlikely to be successful.
(1) Without those who develop CCM software, applied researchers could not analyze their data (pen-and-paper procedures are no reasonable option). However, of the seven multi-version software packages for the R environment listed on the COMPASSS software website (cna, SetMethods, QCA3, QCA/QCAGUI, QCAfalsePositive, QCApro, QCAtools), only four, namely cna, QCA3, QCA/QCAGUI and QCApro provide a log file as part of their distribution where minor and major changes in the functionality or infrastructure between consecutive versions of the package are listed. By means of these log files, users can immediately see whether changes that affect procedures or results have been implemented. With all other CCM software, it is not clear what has changed from version to version, which is highly problematic, all the more so if software is not open source as in the case of fs/QCA. Developers of CCM software should therefore ensure that, even if they do not want to make their source code available, changes between versions are sufficiently documented and new versions are appropriately indicated and numbered.
(2) At least as much of the onus of increasing transparency is on users of CCM software. There are at least three issues that need to be addressed in relation to this group of actors: data availability, the provision of replication "scripts", and proper citation.
Data availability
Sometimes, there are restrictions on access to data, but generally, studies for which the data underlying their findings and conclusions have not been made available lose much credibility. However, if data are made available, they should be provided in a suitable format (TXT, CSV, etc.) for purposes of replication, and not as a table in a PDF or DOC/X file as is currently often the case in social science publications.
Replication scripts
I have reviewed quite a number of CCM manuscript submission so far, but only one of them did include a proper replication script as part of the submission. When software users draw on R packages, there is certainly no reason whatsoever for not submitting a replication script along with the manuscript text, and for publishing this script together with the accepted article. Even with graphical software such as fs/QCA or Tosmana, however, is it possible to provide a replication "script", for example, in the form of a description of the sequence of actions that have been taken in operating the software, from the import of the data to the generation of the final solution, and/or a series of screenshots or, even better, a screen video. There are numerous possibilities, some better than others, but all better than no material.
Proper citation
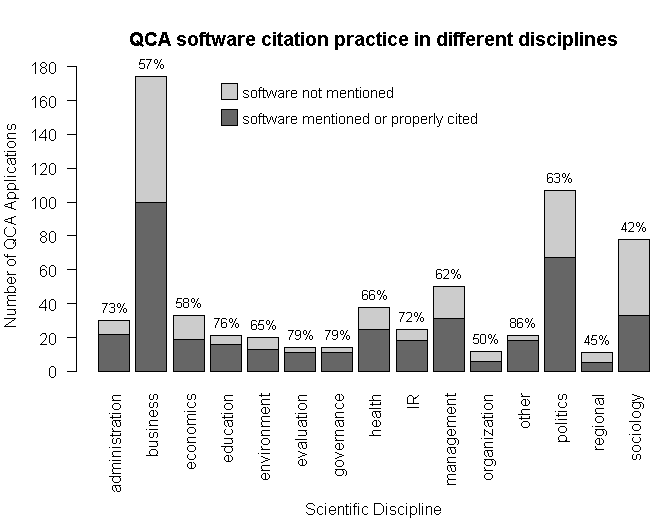
Although one would expect that scientists are conscientious in trying to maintain standards of good scientific publishing, it is surprising to see how rarely users of a particular piece of CCM software cite it. But proper citation is important. It not only acknowledges the work of others that has been used (strictly speaking, everything else is plagiarism), but it also ensures research transparency because different QCA software packages have very different functionality and output very different solutions (see, e.g., Baumgartner and Thiem, 2015; Thiem and Dusa, 2013). The figure below provides an extensive analysis of QCA software citation practices across different disciplines of the social sciences, based on a private data set on QCA publications I have built up over the last five years (885 total) (since I have not made this data set publicly available, you can be skeptical as well, of course).
In the area of business, where most QCA applications have been published by now, not even 60 percent of authors at least mention the software they have used. Political science performs somewhat better with 63 percent, but given the seriousness of the issue, it is still disturbing to see so many applied researchers not acknowledging the work of others that they have used in their own research. The worst performing discipline is sociology, where only 42 percent of authors at least mention the software they have used.
(3) Due to the increasing popularity of methods schools and courses across the social sciences, ever more people teach CCMs to students and researchers at all levels. It should become standard practice for instructors of such courses to integrate the issue of transparency into their teaching. Needless to say, these instructors themselves should also practice what they preach in their own work.
(4) Editors and journal reviewers have an important role to play when it comes to questions of transparency. At least two points require attention. First, and perhaps most easily implementable, journals should require the submission of the data used and suitable replication material so that reviewers get the chance to perform all necessary quality checks on the analysis. The replication script should be provided in a way such that it can be directly read by the respective software. For example, if an R package was used, the replication script should be provided as an R file. The same applies to the data. It makes no sense to provide data sets as tables in a PDF or a DOC/X file, as is still often done, because reviewers and interested readers need to copy or manually re-type these data into an appropriate software for conversion, a process during which many errors may sneak in.
Second, but less easily implementable, if implementable at all anytime soon, the review process itself should be made fully transparent. In other words, (single/double/triple) blind peer review should be abolished because the anonymity of this process produces many scientific distortions, including, for example, the enforcement of inappropriate citations, the suppression of appropriate citations, the unwarranted inclusion or exclusion of theoretical or empirical material, and the misuse of anonymity for influencing private conflicts or otherwise politically instead of scientifically motivated agendas. The full openness of the peer review process would decrease the rate of occurrence of these problems considerably. It would expose all conflicts of interests, it would incentivize reviewers to produce reviews of high scientific quality since their community could evaluate the content of reviews, and it would therefore lead to better science.
(5) In an age of digital publishing, publishers need to provide the necessary infrastructure to help increase transparency. For example, I have only recently managed to make replication files for R available as an online appendix at some SAGE journals. Before, it was apparently technically impossible. The publisher is still having problems, but is seems as if things are gradually improving. Data infrastructure projects such as the Harvard Dataverse software application are laudable attempts at centralizing the open provision of research material, but publishers of scientific literature should improve their direct publication services as well.
References
(1) Without those who develop CCM software, applied researchers could not analyze their data (pen-and-paper procedures are no reasonable option). However, of the seven multi-version software packages for the R environment listed on the COMPASSS software website (cna, SetMethods, QCA3, QCA/QCAGUI, QCAfalsePositive, QCApro, QCAtools), only four, namely cna, QCA3, QCA/QCAGUI and QCApro provide a log file as part of their distribution where minor and major changes in the functionality or infrastructure between consecutive versions of the package are listed. By means of these log files, users can immediately see whether changes that affect procedures or results have been implemented. With all other CCM software, it is not clear what has changed from version to version, which is highly problematic, all the more so if software is not open source as in the case of fs/QCA. Developers of CCM software should therefore ensure that, even if they do not want to make their source code available, changes between versions are sufficiently documented and new versions are appropriately indicated and numbered.
(2) At least as much of the onus of increasing transparency is on users of CCM software. There are at least three issues that need to be addressed in relation to this group of actors: data availability, the provision of replication "scripts", and proper citation.
Data availability
Sometimes, there are restrictions on access to data, but generally, studies for which the data underlying their findings and conclusions have not been made available lose much credibility. However, if data are made available, they should be provided in a suitable format (TXT, CSV, etc.) for purposes of replication, and not as a table in a PDF or DOC/X file as is currently often the case in social science publications.
Replication scripts
I have reviewed quite a number of CCM manuscript submission so far, but only one of them did include a proper replication script as part of the submission. When software users draw on R packages, there is certainly no reason whatsoever for not submitting a replication script along with the manuscript text, and for publishing this script together with the accepted article. Even with graphical software such as fs/QCA or Tosmana, however, is it possible to provide a replication "script", for example, in the form of a description of the sequence of actions that have been taken in operating the software, from the import of the data to the generation of the final solution, and/or a series of screenshots or, even better, a screen video. There are numerous possibilities, some better than others, but all better than no material.
Proper citation
Although one would expect that scientists are conscientious in trying to maintain standards of good scientific publishing, it is surprising to see how rarely users of a particular piece of CCM software cite it. But proper citation is important. It not only acknowledges the work of others that has been used (strictly speaking, everything else is plagiarism), but it also ensures research transparency because different QCA software packages have very different functionality and output very different solutions (see, e.g., Baumgartner and Thiem, 2015; Thiem and Dusa, 2013). The figure below provides an extensive analysis of QCA software citation practices across different disciplines of the social sciences, based on a private data set on QCA publications I have built up over the last five years (885 total) (since I have not made this data set publicly available, you can be skeptical as well, of course).
In the area of business, where most QCA applications have been published by now, not even 60 percent of authors at least mention the software they have used. Political science performs somewhat better with 63 percent, but given the seriousness of the issue, it is still disturbing to see so many applied researchers not acknowledging the work of others that they have used in their own research. The worst performing discipline is sociology, where only 42 percent of authors at least mention the software they have used.
(3) Due to the increasing popularity of methods schools and courses across the social sciences, ever more people teach CCMs to students and researchers at all levels. It should become standard practice for instructors of such courses to integrate the issue of transparency into their teaching. Needless to say, these instructors themselves should also practice what they preach in their own work.
(4) Editors and journal reviewers have an important role to play when it comes to questions of transparency. At least two points require attention. First, and perhaps most easily implementable, journals should require the submission of the data used and suitable replication material so that reviewers get the chance to perform all necessary quality checks on the analysis. The replication script should be provided in a way such that it can be directly read by the respective software. For example, if an R package was used, the replication script should be provided as an R file. The same applies to the data. It makes no sense to provide data sets as tables in a PDF or a DOC/X file, as is still often done, because reviewers and interested readers need to copy or manually re-type these data into an appropriate software for conversion, a process during which many errors may sneak in.
Second, but less easily implementable, if implementable at all anytime soon, the review process itself should be made fully transparent. In other words, (single/double/triple) blind peer review should be abolished because the anonymity of this process produces many scientific distortions, including, for example, the enforcement of inappropriate citations, the suppression of appropriate citations, the unwarranted inclusion or exclusion of theoretical or empirical material, and the misuse of anonymity for influencing private conflicts or otherwise politically instead of scientifically motivated agendas. The full openness of the peer review process would decrease the rate of occurrence of these problems considerably. It would expose all conflicts of interests, it would incentivize reviewers to produce reviews of high scientific quality since their community could evaluate the content of reviews, and it would therefore lead to better science.
(5) In an age of digital publishing, publishers need to provide the necessary infrastructure to help increase transparency. For example, I have only recently managed to make replication files for R available as an online appendix at some SAGE journals. Before, it was apparently technically impossible. The publisher is still having problems, but is seems as if things are gradually improving. Data infrastructure projects such as the Harvard Dataverse software application are laudable attempts at centralizing the open provision of research material, but publishers of scientific literature should improve their direct publication services as well.
References
- Baumgartner, Michael and Alrik Thiem. 2015. "Model Ambiguities in Configurational Comparative Research." Sociological Methods & Research. Advance online publication. DOI: 10.1177/0049124115610351.
- Thiem, Alrik and Adrian Duşa. 2013. "Boolean Minimization in Social Science Research: A Review of Current Software for Qualitative Comparative Analysis (QCA)." Social Science Computer Review 31 (4): 505-521.
Post Reply
-
Ingo Rohlfing
Cologne Center for Comparative Politics, Universität zu Köln - Posts: 20
- Joined: Tue May 24, 2016 5:45 am
Re: QCA-related issues
Alrik makes many good points I briefly want to follow up on. Unfortunately, I think that many issues are not a problem of policy, but of politics, meaning that there largely is agreement what should be done; the problem is to get them implemented (which of course does not speak against the issues that are raised).
1) Software documentation is a good point because it is indirectly related to the issues at stake at the QTD because reproducibility depends on what software you use. For reproducibility, the most important point seems to be proper version numbering. (Is fs/QCA still offered as version 2.5, what it has been for 10 years or so?).
2) I would not insist on reading in a manuscript what software was used. If one uses R, the information could and should be part of the script.
3) I totally agree standards of transpareny should be part of curricula. For QCA/CCM, luckily, this is not too difficult because one can easily draw on established standards in quantitative research, as there is no difference between QCA/CCM and quantitative research when it comes to transparency (post machine-readable data, script, documentation etc., as Alrik describes).
4) I think the issue of non-anonymous peer review is independent of research transparency that is at focus here. It might contribute to better research and reviews, but transparency is another matter. With the Journal Editor Transparency Statement (JETS, http://www.dartstatement.org/#!blank/c22sl), there is progress in making reproduction material available, but it is still some way to go. In psychology, there is an interesting openness initiative encouraing reviewers to insist on transparency before accepting an article for publication (https://opennessinitiative.org/). This could be easily followed by QCA researchersand reviewers.
5) I agree journals could do more, but it is primarily the responsibility of the author to make material available. With Dataverse, QDR, Datadryad etc. there are enough repositories one can use and they offer, in my view, a superior infrastructure to what journals can post on their own website. I would then suffice to include the DOI or another form of a stable URL in a manuscript.
1) Software documentation is a good point because it is indirectly related to the issues at stake at the QTD because reproducibility depends on what software you use. For reproducibility, the most important point seems to be proper version numbering. (Is fs/QCA still offered as version 2.5, what it has been for 10 years or so?).
2) I would not insist on reading in a manuscript what software was used. If one uses R, the information could and should be part of the script.
3) I totally agree standards of transpareny should be part of curricula. For QCA/CCM, luckily, this is not too difficult because one can easily draw on established standards in quantitative research, as there is no difference between QCA/CCM and quantitative research when it comes to transparency (post machine-readable data, script, documentation etc., as Alrik describes).
4) I think the issue of non-anonymous peer review is independent of research transparency that is at focus here. It might contribute to better research and reviews, but transparency is another matter. With the Journal Editor Transparency Statement (JETS, http://www.dartstatement.org/#!blank/c22sl), there is progress in making reproduction material available, but it is still some way to go. In psychology, there is an interesting openness initiative encouraing reviewers to insist on transparency before accepting an article for publication (https://opennessinitiative.org/). This could be easily followed by QCA researchersand reviewers.
5) I agree journals could do more, but it is primarily the responsibility of the author to make material available. With Dataverse, QDR, Datadryad etc. there are enough repositories one can use and they offer, in my view, a superior infrastructure to what journals can post on their own website. I would then suffice to include the DOI or another form of a stable URL in a manuscript.
Post Reply
-
Alrik Thiem
University of Geneva - Posts: 6
- Joined: Fri Oct 21, 2016 7:50 am
Re: QCA-related issues
Dear Ingo, thank you for your replies to the points I have raised. You mention some additional issues that, I believe, are worth being debated more thoroughly in the context of this forum.
For open source software, version numbering may suffice at a minimum (knowledgeable researchers may have a look at the code, but this is certainly not the most transparent way and puts a heavy burden on users of software), but for non-open source software, some kind of a log file must be provided in addition, otherwise, there is no systematic way to find out about changes. fs/QCA has never been properly version-numbered, even though new versions have been posted every 3-6 months, according to the corresponding website. Apparently, new procedures or changes have neither been mentioned, introduced, nor documented (one prime example of this unfortunate practice is probably the PRI measure in the fs/QCA software).
The question is not whether R is used; the question is what R package is used when R is used. The development, programming and verification of software is, generally, scientifically demanding work. Everyone who has ever tried to build an R package knows what I'm talking of here. If that work is used by other researchers, they should properly cite it, all the more so if that software is made available at no charge and users are explicitly asked to use a proper citation before employing the software (e.g., my QCApro package displays a citation note when it is loaded, and so do other R packages).
If one employs such software, and does not properly cite it, that represents an intentionally false citation, or even plagiarism depending on the nature and extent to which that software has been used, and thus an infringement against individual interests according to standards of scientific research integrity, at least in Switzerland. Given the different output different QCA software programs still produce, the suppression of a proper citation in the absence of suitable replication material also negatively affects transparency. Thus, proper citation and the provision of replication material that includes the use of a software program go hand-in-hand. It's the same principle as for the use of data sets that others have originally created. If one wants to use that data set, it should be cited properly.
I don't think the review process itself is separate from what is at stake here. Imagine a reviewer or journal editor asked an author to remove the citation of a software from a manuscript as a condition for acceptance (your position in point (2) is apparently not add odds with such a scenario). Then, clearly, both research transparency AND scientific integrity would suffer. In this connection, I have recently experienced a similar case, where I was asked by a reviewer to remove (in a QCA tutorial) the recommendation that the employed software be properly cited in applied work. That reviewer argued that the citation of software would drive up the citation counts of software developers. Apparently, some researchers are so absorbed by citation counts as a "currency" that they are prepared to sacrifice scientific integrity for it. In principle, any component of a paper or replication script is subject to such conditioning. Making the review process more transparent would thus also mean making the research process more transparent.
If I publish my paper in a journal at SAGE or Oxford, both of which are huge publishers with numerous online resources and capabilities, I could expect that they have the technical means to also make my replication material available on the paper's website. I would always prefer this to a foreign data service where I need to create extra files and again reference these files in the actual paper.
ingorohlfing wrote:1) Software documentation is a good point because it is indirectly related to the issues at stake at the QTD because reproducibility depends on what software you use. For reproducibility, the most important point seems to be proper version numbering. (Is fs/QCA still offered as version 2.5, what it has been for 10 years or so?).
For open source software, version numbering may suffice at a minimum (knowledgeable researchers may have a look at the code, but this is certainly not the most transparent way and puts a heavy burden on users of software), but for non-open source software, some kind of a log file must be provided in addition, otherwise, there is no systematic way to find out about changes. fs/QCA has never been properly version-numbered, even though new versions have been posted every 3-6 months, according to the corresponding website. Apparently, new procedures or changes have neither been mentioned, introduced, nor documented (one prime example of this unfortunate practice is probably the PRI measure in the fs/QCA software).
ingorohlfing wrote:2) I would not insist on reading in a manuscript what software was used. If one uses R, the information could and should be part of the script.
The question is not whether R is used; the question is what R package is used when R is used. The development, programming and verification of software is, generally, scientifically demanding work. Everyone who has ever tried to build an R package knows what I'm talking of here. If that work is used by other researchers, they should properly cite it, all the more so if that software is made available at no charge and users are explicitly asked to use a proper citation before employing the software (e.g., my QCApro package displays a citation note when it is loaded, and so do other R packages).
If one employs such software, and does not properly cite it, that represents an intentionally false citation, or even plagiarism depending on the nature and extent to which that software has been used, and thus an infringement against individual interests according to standards of scientific research integrity, at least in Switzerland. Given the different output different QCA software programs still produce, the suppression of a proper citation in the absence of suitable replication material also negatively affects transparency. Thus, proper citation and the provision of replication material that includes the use of a software program go hand-in-hand. It's the same principle as for the use of data sets that others have originally created. If one wants to use that data set, it should be cited properly.
ingorohlfing wrote:4) I think the issue of non-anonymous peer review is independent of research transparency that is at focus here. It might contribute to better research and reviews, but transparency is another matter. With the Journal Editor Transparency Statement (JETS, http://www.dartstatement.org/#!blank/c22sl), there is progress in making reproduction material available, but it is still some way to go. In psychology, there is an interesting openness initiative encouraing reviewers to insist on transparency before accepting an article for publication (https://opennessinitiative.org/). This could be easily followed by QCA researchersand reviewers.
I don't think the review process itself is separate from what is at stake here. Imagine a reviewer or journal editor asked an author to remove the citation of a software from a manuscript as a condition for acceptance (your position in point (2) is apparently not add odds with such a scenario). Then, clearly, both research transparency AND scientific integrity would suffer. In this connection, I have recently experienced a similar case, where I was asked by a reviewer to remove (in a QCA tutorial) the recommendation that the employed software be properly cited in applied work. That reviewer argued that the citation of software would drive up the citation counts of software developers. Apparently, some researchers are so absorbed by citation counts as a "currency" that they are prepared to sacrifice scientific integrity for it. In principle, any component of a paper or replication script is subject to such conditioning. Making the review process more transparent would thus also mean making the research process more transparent.
ingorohlfing wrote:5) I agree journals could do more, but it is primarily the responsibility of the author to make material available. With Dataverse, QDR, Datadryad etc. there are enough repositories one can use and they offer, in my view, a superior infrastructure to what journals can post on their own website. I would then suffice to include the DOI or another form of a stable URL in a manuscript.
If I publish my paper in a journal at SAGE or Oxford, both of which are huge publishers with numerous online resources and capabilities, I could expect that they have the technical means to also make my replication material available on the paper's website. I would always prefer this to a foreign data service where I need to create extra files and again reference these files in the actual paper.
Post Reply
-
Ingo Rohlfing
Cologne Center for Comparative Politics, Universität zu Köln - Posts: 20
- Joined: Tue May 24, 2016 5:45 am
Re: QCA-related issues
Again, these are excellent points that demonstrate, in my view, that QCA/configurational methods are getting increasingly similar to quantitative methods, but that we have to catch up in terms of making material and the tools we use transparent.
This is true, I agree. I was thinking of some articles stating something like "The analysis was produced with Stata 13.1.". This is better than nothing, but does not help much in reproducing the results. Because I need the raw data and a script for reproduction, one should include information about the OS, the software version and the versions of all packages/ado-files that were used (like described here https://thepoliticalmethodologist.com/2 ... l-science/). However, I fully agree that we should give more credit to software developers and also to the provision of data, meaning one should reference packages and data in the main article (repositories like The Dataverse allow one to export a reference for a dataset to a reference manager).
Certainly, it would be one form of "added value". However, I prefer to prepare my final files in a way that allows me to share them in any form, be it a publisher's website, a repository or by email. This means that I do not see why the format of the reproduction files and appendices should differ depending on where they are posted. Moreover, repositories show you how often the dataset was downloaded and some of them allow for commenting on the posted files, which a publisher's website does not because it is pretty much static. Finally, one should mention in a paper that reproduction material is available. It then does not matter whether you write "Reproduction material is available on publisher's website" or whether you write "Reproduction material is available at [URL]", the stable URL having been assigned by a repository.
Alrik Thiem wrote:The question is not whether R is used; the question is what R package is used when R is used. The development, programming and verification of software is, generally, scientifically demanding work. Everyone who has ever tried to build an R package knows what I'm talking of here. If that work is used by other researchers, they should properly cite it, all the more so if that software is made available at no charge and users are explicitly asked to use a proper citation before employing the software (e.g., my QCApro package displays a citation note when it is loaded, and so do other R packages).
If one employs such software, and does not properly cite it, that represents an intentionally false citation, or even plagiarism depending on the nature and extent to which that software has been used, and thus an infringement against individual interests according to standards of scientific research integrity, at least in Switzerland. Given the different output different QCA software programs still produce, the suppression of a proper citation in the absence of suitable replication material also negatively affects transparency. Thus, proper citation and the provision of replication material that includes the use of a software program go hand-in-hand. It's the same principle as for the use of data sets that others have originally created. If one wants to use that data set, it should be cited properly.
This is true, I agree. I was thinking of some articles stating something like "The analysis was produced with Stata 13.1.". This is better than nothing, but does not help much in reproducing the results. Because I need the raw data and a script for reproduction, one should include information about the OS, the software version and the versions of all packages/ado-files that were used (like described here https://thepoliticalmethodologist.com/2 ... l-science/). However, I fully agree that we should give more credit to software developers and also to the provision of data, meaning one should reference packages and data in the main article (repositories like The Dataverse allow one to export a reference for a dataset to a reference manager).
Alrik Thiem wrote:If I publish my paper in a journal at SAGE or Oxford, both of which are huge publishers with numerous online resources and capabilities, I could expect that they have the technical means to also make my replication material available on the paper's website. I would always prefer this to a foreign data service where I need to create extra files and again reference these files in the actual paper.
Certainly, it would be one form of "added value". However, I prefer to prepare my final files in a way that allows me to share them in any form, be it a publisher's website, a repository or by email. This means that I do not see why the format of the reproduction files and appendices should differ depending on where they are posted. Moreover, repositories show you how often the dataset was downloaded and some of them allow for commenting on the posted files, which a publisher's website does not because it is pretty much static. Finally, one should mention in a paper that reproduction material is available. It then does not matter whether you write "Reproduction material is available on publisher's website" or whether you write "Reproduction material is available at [URL]", the stable URL having been assigned by a repository.
Post Reply
-
Eva Thomann
Re: QCA-related issues
Dear all
In principle I agree that it is possible to establish a high degree of transparency with QCA, relatively regardless of the software used.
I will only briefly and complementarily mention some selected problems from a user's perspective.
1. A couple of major journals still do not offer the possibility of supplementary appendices - for example, Governance. While it is of course possible to provide supplementary material also on another platform, the problem is that it is not possible to provide supplementary material during the review process, if it exceeds the word count. This is a problem because in my experience, 95% of the referees (and readers) especially of American journals know virtually nothing about QCA and are baffled about many things ("the method is esoteric"). Or they did a much-cited QCA 10 years ago and are not familiar with the newer aspects of it (like ESA). Hence I very often get the feedback that I need to explain much more and provide much more documentation - way beyond what would be standard for more mainstream methods. And then, the more transparent you are, the more perplexed the referees get. I guess my point is that transparency with QCA has become easy with journals and referees that are experienced with QCA (JEPP is really an example of good practice) but remains a challenge for other journals. Standards would help - they would be something one could refer to. And there should be some "naming and shaming" mechanism to incentivize journals to provide the possibility of online appendices. See my first, feeble attempt at it here.
2. Robustness tests (calibration and other). We all know now that we should perform robustness tests, but especially if robustness is tested not only for calibration, but also e.g. for raw consistency with differently calibrated data, presentation becomes a challenge. Even more challenging is the evaluation of "how robust" the results actually are, and the choice of the "best" model - it seems to me that we don't really have clear criteria for that at this point. This goes beyond transparency in a way, but then again, if we need to be transparent about robustness but don't really know how to deal with it, then transparency comes at the risk of confusing / swamping reviewers and readers. I am not trying to say that robustness should not be tested for, I am just highlighting a practical challenge. Something equivalent to AIC or BIC would help enormously.
3. I think skewness statistics should be standard when presenting calibration. Skewness has so many implications that transparency about it is essential for interpreting the results.
4. Regarding software/package citation, I agree that it is an important matter of recognition and transparency. But I would also like to point out that the plurality of packages can imply that you have to cite so many packages that it conflicts with the word count. Formulating package citation as a standard (rather than a recommendation) in the main article seems to go way beyond what is practiced in most other methodological fields. Correct me if I'm wrong about this latter point. (I was not that reviewer). Again, highlighting a practical challenge but I also don't have a good solution for it. Perhaps packages could be cited in the online appendix - given that it is not primarily about citation indices?
5. Switching to the reviewer's perspective, lengthy/messy appendices can be a real challenge. From this perspective, too, it would be helpful to have guidelines for authors. Just to give an example, I have seen papers that literally discuss each and every simplifying assumption verbally and in depth in the appendix. Of course that is a noble thing to do, but a table or a Boolean expression together with a verbatim discussion only of especially noteworthy SAs would be a whole lot more efficient to process. Even if the appendix does not contribute to the word count, it should be kept as concise as possible.
Eva Thomann, Heidelberg University, Germany
In principle I agree that it is possible to establish a high degree of transparency with QCA, relatively regardless of the software used.
I will only briefly and complementarily mention some selected problems from a user's perspective.
1. A couple of major journals still do not offer the possibility of supplementary appendices - for example, Governance. While it is of course possible to provide supplementary material also on another platform, the problem is that it is not possible to provide supplementary material during the review process, if it exceeds the word count. This is a problem because in my experience, 95% of the referees (and readers) especially of American journals know virtually nothing about QCA and are baffled about many things ("the method is esoteric"). Or they did a much-cited QCA 10 years ago and are not familiar with the newer aspects of it (like ESA). Hence I very often get the feedback that I need to explain much more and provide much more documentation - way beyond what would be standard for more mainstream methods. And then, the more transparent you are, the more perplexed the referees get. I guess my point is that transparency with QCA has become easy with journals and referees that are experienced with QCA (JEPP is really an example of good practice) but remains a challenge for other journals. Standards would help - they would be something one could refer to. And there should be some "naming and shaming" mechanism to incentivize journals to provide the possibility of online appendices. See my first, feeble attempt at it here.
2. Robustness tests (calibration and other). We all know now that we should perform robustness tests, but especially if robustness is tested not only for calibration, but also e.g. for raw consistency with differently calibrated data, presentation becomes a challenge. Even more challenging is the evaluation of "how robust" the results actually are, and the choice of the "best" model - it seems to me that we don't really have clear criteria for that at this point. This goes beyond transparency in a way, but then again, if we need to be transparent about robustness but don't really know how to deal with it, then transparency comes at the risk of confusing / swamping reviewers and readers. I am not trying to say that robustness should not be tested for, I am just highlighting a practical challenge. Something equivalent to AIC or BIC would help enormously.
3. I think skewness statistics should be standard when presenting calibration. Skewness has so many implications that transparency about it is essential for interpreting the results.
4. Regarding software/package citation, I agree that it is an important matter of recognition and transparency. But I would also like to point out that the plurality of packages can imply that you have to cite so many packages that it conflicts with the word count. Formulating package citation as a standard (rather than a recommendation) in the main article seems to go way beyond what is practiced in most other methodological fields. Correct me if I'm wrong about this latter point. (I was not that reviewer). Again, highlighting a practical challenge but I also don't have a good solution for it. Perhaps packages could be cited in the online appendix - given that it is not primarily about citation indices?
5. Switching to the reviewer's perspective, lengthy/messy appendices can be a real challenge. From this perspective, too, it would be helpful to have guidelines for authors. Just to give an example, I have seen papers that literally discuss each and every simplifying assumption verbally and in depth in the appendix. Of course that is a noble thing to do, but a table or a Boolean expression together with a verbatim discussion only of especially noteworthy SAs would be a whole lot more efficient to process. Even if the appendix does not contribute to the word count, it should be kept as concise as possible.
Eva Thomann, Heidelberg University, Germany
Post Reply
-
Alrik Thiem
University of Geneva - Posts: 6
- Joined: Fri Oct 21, 2016 7:50 am
Re: QCA-related issues
Dear Eva, these are some interesting points from a user's perspective.
Why don't you simply cite the relevant methodological literature you're using? I mean, science is cumulative, and if (applied) reviewers don't know the relevant methodological literature, they should not comment on methodological aspects of your submission, or ask you to explain things that have already been explained elsewhere. If I were an applied researcher submitting an article, and was asked to explain something about the method I used, but which is not directly relevant to my article, I would simply respond in the memorandum of changes that this has already been explained in a much clearer and better way than I could ever do this within the scope of the article in this or that particular piece by this or that particular person, who is a specialist. But my experience is that journals now prefer to have a mix of reviewers, two or three for the applied/theoretical part and one or two methodologically oriented reviewers for the technical part, where these questions are less frequently asked.
I don't think robustness tests contribute anything to transparency. I would assume the way you calibrate your data, you choose your factors, etc. is the optimal one at the time of writing (whatever "optimal" means, of course, you'd have to argue what is "optimal"; it could also be a naive baseline choice). As long you are transparent about these choices, why the need to introduce all kinds of variations in your research design? QCA is a CASE-sensitive method. That it can react to small changes is a key strength of the method, not a weakness.
Everything you write in your paper conflicts with the word count, in that sense, but word count limits cannot be a reason for disregarding standards of scientific integrity. I'm not sure how many packages that require citation you usually need in your work, but if you need so many packages that proper citation becomes a problem for your word limit, then you might want to switch to better / more powerful / versatile packages (or, e.g., try to cut words elsewhere in your text, or write two separate articles, or submit to a journal with a higher word limit).
Appendices are there to provide additional information. Unless an appendix contains information that is of central relevance to the text (e.g., a replication script for the main analysis), I never read it as a reviewer. Tons of robustness tests or general explanations of methodological aspects of QCA, for example, are of no direct relevance.
That authors feel the need to justify their simplifying assumptions is a consequence of a different problem, namely a misunderstanding in the QCA literature that conservative solutions (QCA-CS) make no assumptions, whereas parsimonious solutions (QCA-PS) create the risk for all kinds of problematic assumptions. This is erroneous. First of all, whether remainders are used at all is a question of the algorithm that is employed. For example, the eQMC algorithm in the QCApro needs no assumptions whatsoever for QCA-PS, just like CNA. But when used with Quine-McCluskey optimization, QCA-CS declares all remainders to be not sufficient for the outcome, which requires much stronger assumptions that declaring remainders to be sufficient (just do the Boolean math for what is means for something to be [not] sufficient for something else.)
Eva Thomann wrote:1. [...] I very often get the feedback that I need to explain much more and provide much more documentation - way beyond what would be standard for more mainstream methods. And then, the more transparent you are, the more perplexed the referees get.
Why don't you simply cite the relevant methodological literature you're using? I mean, science is cumulative, and if (applied) reviewers don't know the relevant methodological literature, they should not comment on methodological aspects of your submission, or ask you to explain things that have already been explained elsewhere. If I were an applied researcher submitting an article, and was asked to explain something about the method I used, but which is not directly relevant to my article, I would simply respond in the memorandum of changes that this has already been explained in a much clearer and better way than I could ever do this within the scope of the article in this or that particular piece by this or that particular person, who is a specialist. But my experience is that journals now prefer to have a mix of reviewers, two or three for the applied/theoretical part and one or two methodologically oriented reviewers for the technical part, where these questions are less frequently asked.
Eva Thomann wrote:2. Robustness tests (calibration and other). We all know now that we should perform robustness tests, [...] but then again, if we need to be transparent about robustness but don't really know how to deal with it, then transparency comes at the risk of confusing / swamping reviewers and readers. I am not trying to say that robustness should not be tested for, I am just highlighting a practical challenge. Something equivalent to AIC or BIC would help enormously.
I don't think robustness tests contribute anything to transparency. I would assume the way you calibrate your data, you choose your factors, etc. is the optimal one at the time of writing (whatever "optimal" means, of course, you'd have to argue what is "optimal"; it could also be a naive baseline choice). As long you are transparent about these choices, why the need to introduce all kinds of variations in your research design? QCA is a CASE-sensitive method. That it can react to small changes is a key strength of the method, not a weakness.
Eva Thomann wrote:4. Regarding software/package citation, I agree that it is an important matter of recognition and transparency. But I would also like to point out that the plurality of packages can imply that you have to cite so many packages that it conflicts with the word count.
Everything you write in your paper conflicts with the word count, in that sense, but word count limits cannot be a reason for disregarding standards of scientific integrity. I'm not sure how many packages that require citation you usually need in your work, but if you need so many packages that proper citation becomes a problem for your word limit, then you might want to switch to better / more powerful / versatile packages (or, e.g., try to cut words elsewhere in your text, or write two separate articles, or submit to a journal with a higher word limit).
Eva Thomann wrote:5. Switching to the reviewer's perspective, lengthy/messy appendices can be a real challenge. [...] I have seen papers that literally discuss each and every simplifying assumption verbally and in depth in the appendix. Of course that is a noble thing to do [...].
Appendices are there to provide additional information. Unless an appendix contains information that is of central relevance to the text (e.g., a replication script for the main analysis), I never read it as a reviewer. Tons of robustness tests or general explanations of methodological aspects of QCA, for example, are of no direct relevance.
That authors feel the need to justify their simplifying assumptions is a consequence of a different problem, namely a misunderstanding in the QCA literature that conservative solutions (QCA-CS) make no assumptions, whereas parsimonious solutions (QCA-PS) create the risk for all kinds of problematic assumptions. This is erroneous. First of all, whether remainders are used at all is a question of the algorithm that is employed. For example, the eQMC algorithm in the QCApro needs no assumptions whatsoever for QCA-PS, just like CNA. But when used with Quine-McCluskey optimization, QCA-CS declares all remainders to be not sufficient for the outcome, which requires much stronger assumptions that declaring remainders to be sufficient (just do the Boolean math for what is means for something to be [not] sufficient for something else.)
Post Reply
-
Eva Thomann
Heidelberg University - Posts: 3
- Joined: Fri Nov 11, 2016 2:23 pm
Re: QCA-related issues
Hi Alrik
Thank you very much for your constructive and interesting comments. Just three points of clarification: I was not seeking advice on how to respond to referees (I AM an applied researcher, and trust me, it is rarely that simple in practice), but illustrating why it is important that journals allow for supplementary appendices. Similarly, nothing in my comments should be understood as suggestions to disregard scientific integrity – I agree with you that the further consolidation of R packages is certainly a welcome development that mediates the problem. Finally, whether or not it is useful to perform robustness tests, justify counterfactual arguments, and review supplementary appendices seems to be partly a matter of perspective, partly subject to ongoing methodological debates whose settlement probably goes beyond the purpose of this forum. In my view, as long as a substantive set of scholars grant importance to these issues, the related challenges should be addressed.
Best wishes
Eva
Thank you very much for your constructive and interesting comments. Just three points of clarification: I was not seeking advice on how to respond to referees (I AM an applied researcher, and trust me, it is rarely that simple in practice), but illustrating why it is important that journals allow for supplementary appendices. Similarly, nothing in my comments should be understood as suggestions to disregard scientific integrity – I agree with you that the further consolidation of R packages is certainly a welcome development that mediates the problem. Finally, whether or not it is useful to perform robustness tests, justify counterfactual arguments, and review supplementary appendices seems to be partly a matter of perspective, partly subject to ongoing methodological debates whose settlement probably goes beyond the purpose of this forum. In my view, as long as a substantive set of scholars grant importance to these issues, the related challenges should be addressed.
Best wishes
Eva
Post Reply
-
Alrik Thiem
University of Geneva - Posts: 6
- Joined: Fri Oct 21, 2016 7:50 am
Re: QCA-related issues
Dear Eva, many thanks for your reply.
I absolutely believe you when you say that it is often not that simple to react appropriately to reviewers who ask questions regarding QCA that would not normally be asked if another, more "traditional" method had been used. On the one hand, you, of course, want to please reviewers and get your piece published as quickly as possible, but on the other, you think that you should not always have to explain what QCA is or what it does.
Have you ever tried what I suggested, or did you always comply and produce additional documentation on basic aspects of QCA when you were asked to do so? My experience as a methodologist is that, as long as you remain polite in pointing reviewers to important methodological material that provides the basis for your analysis, and argue that you would rather need the space in your article for better theory development or more thorough result interpretation, they will not take this as you being unresponsive to their concerns. Even if some reviewer, as you mention, considers QCA to be too "esoteric", then why not list ten articles that have used QCA in some of the most well-known journals in sociology, political science, administration or management in your response to this reviewer? Believe me, I don't want to suggest what you should write to reviewers. You will know best yourself. But I think applied users like you could be a little more assertive in responding to reviewers who ask them to produce documentation or supplementary material that is a considerable waste of research time and journal space.
I absolutely believe you when you say that it is often not that simple to react appropriately to reviewers who ask questions regarding QCA that would not normally be asked if another, more "traditional" method had been used. On the one hand, you, of course, want to please reviewers and get your piece published as quickly as possible, but on the other, you think that you should not always have to explain what QCA is or what it does.
Have you ever tried what I suggested, or did you always comply and produce additional documentation on basic aspects of QCA when you were asked to do so? My experience as a methodologist is that, as long as you remain polite in pointing reviewers to important methodological material that provides the basis for your analysis, and argue that you would rather need the space in your article for better theory development or more thorough result interpretation, they will not take this as you being unresponsive to their concerns. Even if some reviewer, as you mention, considers QCA to be too "esoteric", then why not list ten articles that have used QCA in some of the most well-known journals in sociology, political science, administration or management in your response to this reviewer? Believe me, I don't want to suggest what you should write to reviewers. You will know best yourself. But I think applied users like you could be a little more assertive in responding to reviewers who ask them to produce documentation or supplementary material that is a considerable waste of research time and journal space.
Post Reply
-
Eva Thomann
Heidelberg University - Posts: 3
- Joined: Fri Nov 11, 2016 2:23 pm
Re: QCA-related issues
Hi Alrik
Personally, if someone tells me what I write is overly complex or unclear, I try to address such concerns because reaching and convincing the reader is my goal Nr. 1. But yours are precisely the arguments that justify why some of this information might be better placed in an online appendix. Thanks a lot for all the concrete tips - really useful, not only for me, I suppose!
Best wishes
Eva
Personally, if someone tells me what I write is overly complex or unclear, I try to address such concerns because reaching and convincing the reader is my goal Nr. 1. But yours are precisely the arguments that justify why some of this information might be better placed in an online appendix. Thanks a lot for all the concrete tips - really useful, not only for me, I suppose!
Best wishes
Eva
Post Reply
-
Alrik Thiem
University of Geneva - Posts: 6
- Joined: Fri Oct 21, 2016 7:50 am
Re: QCA-related issues
EvaThomann wrote:Hi Alrik
Personally, if someone tells me what I write is overly complex or unclear, I try to address such concerns because reaching and convincing the reader is my goal Nr. 1. But yours are precisely the arguments that justify why some of this information might be better placed in an online appendix. Thanks a lot for all the concrete tips - really useful, not only for me, I suppose!
Eva
Hi Eva, I was not referring to situations when reviewers tell you that what you have written is unclear or unconvincing. Needless to say, you should address such concerns in all necessary detail in your paper or/and author response sheet. What I was referring to when saying that you may want to try and point reviewers to existing methodological publications instead of repeating everything that has been said already in your own annexed documentation file (possibly including misinterpretations or even errors [the Chinese whispers effect]) is your complaint that "[...] 95% of the referees (and readers) especially of American journals know virtually nothing about QCA and are baffled about many things [...]. Hence I very often get the feedback that I need to explain much more and provide much more documentation - way beyond what would be standard for more mainstream methods."
Of course, I can't give you any guarantees that what I suggested you could do when being faced again with criticism of the kind "QCA is too esoteric" will help in the particular community you're addressing (administration, evaluation, governance, public policy?). But I think it's worth trying. Please let me know about your experiences.
Post Reply
-
Ingo Rohlfing
Cologne Center for Comparative Politics, Universität zu Köln - Posts: 20
- Joined: Tue May 24, 2016 5:45 am
Re: QCA-related issues
A short summary post on Alrik's and Eva's interesting discussion:
1) I am surprised that some journals do not accept appendices. If you want to post an appendix online, on Dataverse or so, then this should not count against the word limit and the journal should pass forward the appendix to the reviewers. But if this is not the editorial policy, then you have to live with it, mention the appendix in the manuscript and post it online if the article gets published.
2) Whether you should do robustness tests is not a matter of transparency, I agree, but you need to report them if you do them (I cannot imagine a truth table analysis where robustness tests can be dispensed with, but this is another matter). The reviewers still can decide whether to read it or not. In the transparency debate, it is sometimes argued "Why do we need appendices, no one reads them?". I think this is wrong, as download numbers on Dataverse suggests, and it confuses the claim that people should be able to access an appendix with the claim that most people will do it.
3) Proper citation of packages does count against the word limit, but I fully agree with Alrik that this holds for any publication you cite. The "simple" fix is that the references do not count against the word limit, but this is again an editorial policy.
1) I am surprised that some journals do not accept appendices. If you want to post an appendix online, on Dataverse or so, then this should not count against the word limit and the journal should pass forward the appendix to the reviewers. But if this is not the editorial policy, then you have to live with it, mention the appendix in the manuscript and post it online if the article gets published.
2) Whether you should do robustness tests is not a matter of transparency, I agree, but you need to report them if you do them (I cannot imagine a truth table analysis where robustness tests can be dispensed with, but this is another matter). The reviewers still can decide whether to read it or not. In the transparency debate, it is sometimes argued "Why do we need appendices, no one reads them?". I think this is wrong, as download numbers on Dataverse suggests, and it confuses the claim that people should be able to access an appendix with the claim that most people will do it.
3) Proper citation of packages does count against the word limit, but I fully agree with Alrik that this holds for any publication you cite. The "simple" fix is that the references do not count against the word limit, but this is again an editorial policy.
Post Reply
-
Carsten Schneider
Central European University - Posts: 4
- Joined: Fri Apr 08, 2016 3:40 am
Re: QCA-related issues
Dear All
As the working group's co-organizer, I want to thoroughly thank all of you who are contributing to this important debate in such a helpful manner!
Before making a suggestion, I have just one minor question on the points raised so far:
When Eva mentions that proper package citation might create problems with the word limit, I understood it such that she proposes that not only the main package used must be properly cited (I fully agree), but also all the other packages on which the main package depends. Maybe a short word of clarification on what transparent practices should dictate would be helpful here.
The suggestion I would like to make comes from the organizers of the entire deliberation process, Alan Jacobs and Tim Buethe. Among other things, they ask working groups to try and put forward published examples of good transparency practice. I am sure it would not be a problem to put forward own publications.
One outcome of the entire discussion will be some written document that reflects the discussions and formulates suggestion on how to handle transparency. With this goal in mind, we may want to continue the discussion with the following general points in mind (I quote from Alan's and Tim's message all WG co-organizers received):
We would ask you to organize your evaluation of specific practices under four
broad headings, which we expect to be of considerable heuristic value to readers:
a. Valued current practices: Practices that are currently widely used
and widely accepted as valuable research practices.
b. Low-cost improvements/innovations: Emergent, innovative, or
adapted practices that are not currently in wide use but that may prove
to be valuable for many research designs and that, when intellectually
appropriate, could be carried out at modest cost and without significant
risk to human subjects.
c. Practices for cautious assessment/selective use: Proposed or
emergent practices that might yield substantial transparency benefits
for some research designs, but may also involve substantial
epistemological tensions, methodological compromises, costs, or
ethical/safety risks. The Working Group might draw attention to
specific examples of political science research employing particular
practices in this category, but would advise researchers to carefully
weigh these practices’ advantages and disadvantages before pursuing
them. Practices in this category would also be ones that the Working
Group would discourage journal editors, reviewers, granting agencies,
or others from setting up as norms or requirements because of their
high costs or unsuitability for some kinds of research or research
contexts.
d. Inadvisable practices: Practices that the Working Group strongly discourages, at least for particular kinds of research or research contexts. Practices in this category would also be ones that the Working Group would strongly advise journal editors, reviewers, granting agencies, and others not to set up as norms or standards even if individual scholars might find them useful in their own work.
As the working group's co-organizer, I want to thoroughly thank all of you who are contributing to this important debate in such a helpful manner!
Before making a suggestion, I have just one minor question on the points raised so far:
When Eva mentions that proper package citation might create problems with the word limit, I understood it such that she proposes that not only the main package used must be properly cited (I fully agree), but also all the other packages on which the main package depends. Maybe a short word of clarification on what transparent practices should dictate would be helpful here.
The suggestion I would like to make comes from the organizers of the entire deliberation process, Alan Jacobs and Tim Buethe. Among other things, they ask working groups to try and put forward published examples of good transparency practice. I am sure it would not be a problem to put forward own publications.
One outcome of the entire discussion will be some written document that reflects the discussions and formulates suggestion on how to handle transparency. With this goal in mind, we may want to continue the discussion with the following general points in mind (I quote from Alan's and Tim's message all WG co-organizers received):
We would ask you to organize your evaluation of specific practices under four
broad headings, which we expect to be of considerable heuristic value to readers:
a. Valued current practices: Practices that are currently widely used
and widely accepted as valuable research practices.
b. Low-cost improvements/innovations: Emergent, innovative, or
adapted practices that are not currently in wide use but that may prove
to be valuable for many research designs and that, when intellectually
appropriate, could be carried out at modest cost and without significant
risk to human subjects.
c. Practices for cautious assessment/selective use: Proposed or
emergent practices that might yield substantial transparency benefits
for some research designs, but may also involve substantial
epistemological tensions, methodological compromises, costs, or
ethical/safety risks. The Working Group might draw attention to
specific examples of political science research employing particular
practices in this category, but would advise researchers to carefully
weigh these practices’ advantages and disadvantages before pursuing
them. Practices in this category would also be ones that the Working
Group would discourage journal editors, reviewers, granting agencies,
or others from setting up as norms or requirements because of their
high costs or unsuitability for some kinds of research or research
contexts.
d. Inadvisable practices: Practices that the Working Group strongly discourages, at least for particular kinds of research or research contexts. Practices in this category would also be ones that the Working Group would strongly advise journal editors, reviewers, granting agencies, and others not to set up as norms or standards even if individual scholars might find them useful in their own work.
Post Reply
-
Ingo Rohlfing
Cologne Center for Comparative Politics, Universität zu Köln - Posts: 20
- Joined: Tue May 24, 2016 5:45 am
Re: QCA-related issues
My reponse to Carsten's good points:
I am not the expert on this, but I believe that dependencies do not have to be cited. Eva might clarify what and how many packages she had in mind. If one first does some data wrangling, one might additionally use dplyr and tidyr or ggplot for plotting. But I think the number of packages should not be large and the problem for staying within the word limit should be limited (and if the goal is to save words, one might use Base R instead of these packages).
This sounds like a good classification of transparency issues. I do not have a strong opinion about what issue falls under what category. My hunch is that category (d) only pertains to matters that are not generic to a truth table analysis such as granting access to sensitive data (e.g., interviews) used for deriving sets. I cannot imagine what actual data analysis element would be inadvisable. But I am interested in the views of other contributors to this thread that probably differ from mine.
cschneid wrote:Before making a suggestion, I have just one minor question on the points raised so far:
When Eva mentions that proper package citation might create problems with the word limit, I understood it such that she proposes that not only the main package used must be properly cited (I fully agree), but also all the other packages on which the main package depends. Maybe a short word of clarification on what transparent practices should dictate would be helpful here.
I am not the expert on this, but I believe that dependencies do not have to be cited. Eva might clarify what and how many packages she had in mind. If one first does some data wrangling, one might additionally use dplyr and tidyr or ggplot for plotting. But I think the number of packages should not be large and the problem for staying within the word limit should be limited (and if the goal is to save words, one might use Base R instead of these packages).
cschneid wrote:We would ask you to organize your evaluation of specific practices under four
broad headings, which we expect to be of considerable heuristic value to readers:
a. Valued current practices: Practices that are currently widely used
and widely accepted as valuable research practices.
b. Low-cost improvements/innovations: Emergent, innovative, or
adapted practices that are not currently in wide use but that may prove
to be valuable for many research designs and that, when intellectually
appropriate, could be carried out at modest cost and without significant
risk to human subjects.
c. Practices for cautious assessment/selective use: Proposed or
emergent practices that might yield substantial transparency benefits
for some research designs, but may also involve substantial
epistemological tensions, methodological compromises, costs, or
ethical/safety risks. The Working Group might draw attention to
specific examples of political science research employing particular
practices in this category, but would advise researchers to carefully
weigh these practices’ advantages and disadvantages before pursuing
them. Practices in this category would also be ones that the Working
Group would discourage journal editors, reviewers, granting agencies,
or others from setting up as norms or requirements because of their
high costs or unsuitability for some kinds of research or research
contexts.
d. Inadvisable practices: Practices that the Working Group strongly discourages, at least for particular kinds of research or research contexts. Practices in this category would also be ones that the Working Group would strongly advise journal editors, reviewers, granting agencies, and others not to set up as norms or standards even if individual scholars might find them useful in their own work.
This sounds like a good classification of transparency issues. I do not have a strong opinion about what issue falls under what category. My hunch is that category (d) only pertains to matters that are not generic to a truth table analysis such as granting access to sensitive data (e.g., interviews) used for deriving sets. I cannot imagine what actual data analysis element would be inadvisable. But I am interested in the views of other contributors to this thread that probably differ from mine.
Post Reply
-
Guest
Re: QCA-related issues
Hi Ingo
On your point 1): yes, I am referring to situations when journals do not allow you to submit online appendices for peer review. Maybe next time I should insist and clarify that I want to submit the appendix for review even if it will not be put online on the journal website. But more generally, if this initiative here leads journals to reconsider this practice, I think that would be beneficial from the viewpoint of transparency.
As to package citation: this was indeed only a minor point. The situation has improved now, but there was a time when I needed to use the packages QCA(GUI), SetMethods and QCAtools to do everything I wanted to do. Not mentioning the additional packages used for describing and managing the data. At some point citing each package becomes impractical. Again, I don't think this is a major issue.
Best wishes
Eva
On your point 1): yes, I am referring to situations when journals do not allow you to submit online appendices for peer review. Maybe next time I should insist and clarify that I want to submit the appendix for review even if it will not be put online on the journal website. But more generally, if this initiative here leads journals to reconsider this practice, I think that would be beneficial from the viewpoint of transparency.
As to package citation: this was indeed only a minor point. The situation has improved now, but there was a time when I needed to use the packages QCA(GUI), SetMethods and QCAtools to do everything I wanted to do. Not mentioning the additional packages used for describing and managing the data. At some point citing each package becomes impractical. Again, I don't think this is a major issue.
Best wishes
Eva
Post Reply
-
Eva Thomann
Heidelberg University - Posts: 3
- Joined: Fri Nov 11, 2016 2:23 pm
Re: QCA-related issues
Hi Ingo
On your point 1): yes, I am referring to situations when journals do not allow you to submit online appendices for peer review. Maybe next time I should insist and clarify that I want to submit the appendix for review even if it will not be put online on the journal website. But more generally, if this initiative here leads journals to reconsider this practice, I think that would be beneficial from the viewpoint of transparency.
As to package citation: this was indeed only a minor point. The situation has improved now, but there was a time when I needed to use the packages QCA(GUI), SetMethods and QCAtools to do everything I wanted to do. Not mentioning the additional packages used for describing and managing the data. At some point citing each package becomes impractical. Again, I don't think this is a major issue.
Best wishes
Eva
On your point 1): yes, I am referring to situations when journals do not allow you to submit online appendices for peer review. Maybe next time I should insist and clarify that I want to submit the appendix for review even if it will not be put online on the journal website. But more generally, if this initiative here leads journals to reconsider this practice, I think that would be beneficial from the viewpoint of transparency.
As to package citation: this was indeed only a minor point. The situation has improved now, but there was a time when I needed to use the packages QCA(GUI), SetMethods and QCAtools to do everything I wanted to do. Not mentioning the additional packages used for describing and managing the data. At some point citing each package becomes impractical. Again, I don't think this is a major issue.
Best wishes
Eva
Post Reply
-
Guest
Re: QCA-related issues
Hello all,
This is a very interesting discussion. Transparency is a key issue for the development of social sciences.
I guess I've a radical point of view on the topic: in my opinion, it is always better to be more transparent. The structure of incentives of academic careers pushes researchers to publish (and publish a lot). Given that it's harder to publish a result that is not clear-cut, we fear the risk of seeing fraudulent papers published if we do not impose transparency as a gatekeeper. I'm not saying that all researchers are dishonest, but even one single fraudulent paper can harm the whole discipline for a long time (see the LaCour-Green gate last year).
But I don't think that it is the role of researchers to impose transparency standards. There is a collective action problem here. If a researcher is more transparent than her peers, she will publish less (because her results will be, on average, more "mixed" than those of her peers). And that will harm her career. To me, it the role of editors to impose strong transparency standards.
Editors should at least force researchers to publish the material to replicate the analysis. It tends to become the norm for quantitative papers, and this should, in my opinion also be the norm for QCA papers. I think editors should at least impose that researchers release:
(1) their data (the truth table and the raw data of all relevant information used to create this truth table)
(2) their replication script
Best regards,
Damien Bol
King's College London
This is a very interesting discussion. Transparency is a key issue for the development of social sciences.
I guess I've a radical point of view on the topic: in my opinion, it is always better to be more transparent. The structure of incentives of academic careers pushes researchers to publish (and publish a lot). Given that it's harder to publish a result that is not clear-cut, we fear the risk of seeing fraudulent papers published if we do not impose transparency as a gatekeeper. I'm not saying that all researchers are dishonest, but even one single fraudulent paper can harm the whole discipline for a long time (see the LaCour-Green gate last year).
But I don't think that it is the role of researchers to impose transparency standards. There is a collective action problem here. If a researcher is more transparent than her peers, she will publish less (because her results will be, on average, more "mixed" than those of her peers). And that will harm her career. To me, it the role of editors to impose strong transparency standards.
Editors should at least force researchers to publish the material to replicate the analysis. It tends to become the norm for quantitative papers, and this should, in my opinion also be the norm for QCA papers. I think editors should at least impose that researchers release:
(1) their data (the truth table and the raw data of all relevant information used to create this truth table)
(2) their replication script
Best regards,
Damien Bol
King's College London
Post Reply
-
Adrian Dusa
University of Bucharest - Posts: 1
- Joined: Thu Dec 15, 2016 5:24 am
Re: QCA-related issues
Dear All,
I find this topic extremely interesting for the community, and only very recently have been made aware of this forum's existence.
Very much agree that replication files are key to ensuring reproducibility of research results, and open source software such as R do help a lot. This thread raises a lot of interesting topics, each deserving a dedicated discussion, but I naturally feel compelled to intervene on the software citation part.
Many users, too often (severely) underestimate the amount of effort put into software development, and far too often take it for granted. As if software would grow in the garden, waiting for the right time to be picked up. Developers dedicate years, sometimes even decades (this year there are exactly 10 years from my first version of the QCA package in R) into delivering quality products that are bug-free and user-friendly. And in the case of open-source software, these are free for all.
This kind of effort, and the associated time spent, probably surpasses the effort of writing an article. Researchers don't seem to have even the slightest reservation citing articles, even when this obviously conflicts with the word count... but that doesn't seem to be the case with software.
I believe Ingo is right, dependencies need not be cited because they are further cited by the main packages. Somehow, I find this (mis)interpretation rather strange, to consider that software citation is any different from normal article / book citation. No one asks to cite Aristotle, if subsequent publications are based on his work... why would software be any different?
There is even more about open source software that users don't seem to be aware: they _are_ licensed under some kind of general public license, and I am almost certain that all these licenses _require_ users to cite. By using a GPL licensed software, users don't pay anything but I believe there is a legal obligation to cite (which is not the case with commercial software, which users pay for). A legal expert might have a more professional opinion, but this is how I understand it: not citing the software is a breach of the GPL license. Who doesn't agree with the license (i.e. doesn't want to cite) should not use the package in the first place.
Eva, are you serious...?!
Really, when did citing each and every article mentioned in the text, ever became impractical? Or what definition is used for the word "impractical"?
If using a function from package X, then package X should be cited, period. Just like citing an article, no difference whatsoever.
That is not only a proper scientific behavior, but I believe even (legally) mandatory given the acceptance of the GPL license under which the package is released...
I hope this helps,
Adrian
I find this topic extremely interesting for the community, and only very recently have been made aware of this forum's existence.
Very much agree that replication files are key to ensuring reproducibility of research results, and open source software such as R do help a lot. This thread raises a lot of interesting topics, each deserving a dedicated discussion, but I naturally feel compelled to intervene on the software citation part.
Many users, too often (severely) underestimate the amount of effort put into software development, and far too often take it for granted. As if software would grow in the garden, waiting for the right time to be picked up. Developers dedicate years, sometimes even decades (this year there are exactly 10 years from my first version of the QCA package in R) into delivering quality products that are bug-free and user-friendly. And in the case of open-source software, these are free for all.
This kind of effort, and the associated time spent, probably surpasses the effort of writing an article. Researchers don't seem to have even the slightest reservation citing articles, even when this obviously conflicts with the word count... but that doesn't seem to be the case with software.
ingorohlfing wrote:I am not the expert on this, but I believe that dependencies do not have to be cited.
I believe Ingo is right, dependencies need not be cited because they are further cited by the main packages. Somehow, I find this (mis)interpretation rather strange, to consider that software citation is any different from normal article / book citation. No one asks to cite Aristotle, if subsequent publications are based on his work... why would software be any different?
There is even more about open source software that users don't seem to be aware: they _are_ licensed under some kind of general public license, and I am almost certain that all these licenses _require_ users to cite. By using a GPL licensed software, users don't pay anything but I believe there is a legal obligation to cite (which is not the case with commercial software, which users pay for). A legal expert might have a more professional opinion, but this is how I understand it: not citing the software is a breach of the GPL license. Who doesn't agree with the license (i.e. doesn't want to cite) should not use the package in the first place.
EvaThomann wrote:As to package citation: this was indeed only a minor point. The situation has improved now, but there was a time when I needed to use the packages QCA(GUI), SetMethods and QCAtools to do everything I wanted to do. Not mentioning the additional packages used for describing and managing the data. At some point citing each package becomes impractical. Again, I don't think this is a major issue.
Eva, are you serious...?!
Really, when did citing each and every article mentioned in the text, ever became impractical? Or what definition is used for the word "impractical"?
If using a function from package X, then package X should be cited, period. Just like citing an article, no difference whatsoever.
That is not only a proper scientific behavior, but I believe even (legally) mandatory given the acceptance of the GPL license under which the package is released...
I hope this helps,
Adrian
Post Reply
-
Benoît Rihoux
Université catholique de Louvain (UCL) - Posts: 1
- Joined: Thu Dec 15, 2016 3:48 am
Re: QCA-related issues
Dear all,
As much as I appreciate the effort and potential interest to have a collective discussion on “research transparency” (this is a preoccupation I think we should all have as researchers, regardless of the discipline and methodological toolbox), I must say that I am a bit reluctant to engage directly in a narrow/technical discussion on the QCA ‘analytical moment’ as is suggested by Carsten. The fundamental reason is that there are – I think – much broader issues at stake, not only in methodological terms but also in ‘political’ terms. So: after having read the discussion thread above, and after having quickly consulted a few contributions around the whole DA-RT thing (impressive how much time and energy has been consumed thus far in this whole enterprise!), I feel the need to first provide a (much) broader picture, with attached notes of caution. I think we should never engage in any ‘technical’ discussion without prior consideration of broader issues at stake. So I will structure my thoughts in 4 points:
1/ the broader ‘political’ picture
2/ the broader scientific picture: why ‘transparency’ in priority? Why not other research qualities?
3/ broader than QCA: the so-called ‘qualitative’ territory (and why I object to that label)
4/ and finally QCA proper & how I would view the ‘transparency _and_ other qualities’ recommendations
NB what follows below is a bit short/blunt & would probably deserve more nuances, elaboration etc., but… I simply have no time right now to write more & I’d like to post my comments before the late 2016 deadline.
1/ The broader ‘political’ picture
Having observed the evolution of debates around political science / social science methods over the last 20 years or so, I am clearly a skeptic (NB: I did not write ‘opponent’) of the whole DA-RT initiative.
To put it short, my simple/quick ‘political’ reading of the whole context that has led to this initiative is the fact that political science (well, social sciences more broadly) are being questioned in terms of their ‘scientificity’ (two keywords in the DA-RT framing docs: “credibility” and “legitimacy”), specifically in the U.S., and vis-à-vis presumably ‘real’ sciences, e.g. experimental & natural sciences, and closer to them some more ‘scientific’(?) disciplines such as economics. Hence the need to demonstrate, somewhat defensively, that indeed there is a ‘science of politics’ – in very concrete terms in order to keep some legitimacy _and_ funding, academic positions and the like. And even more so on the ‘qualitative’ side of political science, which is fighting to gain some scientific legitimacy vis-à-vis the ‘quantitative’ mainstream, and which has precisely created the APSA’s Organized Section for Qualitative and Multi-Method Research (QMMR). I see the whole QTD initiative (launched by that QMMR Section) as a logical continuation in those (mainly U.S.) strategic moves.
I dislike this context, and in fact as seen from Europe I feel quite remote from it. But indeed the broader situation is that social sciences (sociology even more so than political science, I’d say) are seriously in trouble in the ‘global scientific competition’ – and this goes way beyond issues of methods and transparency.
And one reason I really dislike this context is that, hence, only a small segment of sciences (social sciences narrowly defined) sort of feels compelled to engage in that sort of self-justification (OK, this is a negative framing – in favorable terms, one could also argue that this is ‘consolidation’). The end result could prove to be: creating further ‘noise’ (masses of at least partly contradictory or complex positions), thereby further weakening political science/social sciences in the ‘global race’.
2/ The broader scientific picture: why ‘transparency’ in priority? Why not other research qualities?
Here I very much agree with Peter Hall’s points, as he discusses in a recent – and very pondered -- contribution of his in the Comparative Methods Newsletter (Vol. 26, issue 1, 2016, pp. 28-31): “what social scientists should value most highly is not transparency, but the integrity of research, understood as research that reflects an honest and systematic search for truths about society, the economy, or politics. In its various dimensions, transparency is a means toward that end. But it is only one of several such means (…)” (p. 28).
I think the more useful discussion we should have should not revolve solely around “transparency”, but rather on: “what is good [social] science?” or “what is sound [social] scientific work”?
According to me, “sound scientific work” comprises at least three main dimensions – and these are (or should be) universal, I mean across all sciences:
• Formulate a clear ontological/epistemological position (there are many valid positions, but they should be formulated) [NB: in many ‘hard sciences’ publications, this is missing!]
• Develop and implement a sound protocol (i.e. practical operations) – in here there are multiple sub-dimensions, and transparency is only one out of certainly 5 or 6 core sub-dimensions that are at least as important. One other point is, for instance: the adequacy of the protocol to the object(s) and research question(s) at hand. This point, for me, is more fundamental than “transparency” (transparency is already one level down, more at the technical/practical level)
• Keep a reflexive view as ‘scientific crafts(wo)man” – this should be true in all sciences. Nothing should ever be seen as obvious, as ‘definite truth’, as ‘the sole & best protocol’, etc. [again, in many ‘hard sciences’ publications, this is seldom question done]
So: “transparency”, for me, is only one sub-point in a much broader set of three transversal points, and I feel it extremely limitative to be constrained to limit oneself to that sub-point.
3/ Broader than QCA: the so-called ‘qualitative’ territory (and why I object to that label)
The more I do research, the less I find the ‘quantitative’ and ‘qualitative’ labels appropriate. Most researchers who conduct an in-depth case study (allegedly an ideal-type of “qualitative” research) frequently use numbers, statistics, descriptive at the very least. And most scholars who engage in survey research and produce numerically coded ‘data sets’ (matrix-type data) in fact are tapping and labelling ‘qualitative’ variations through the concepts they use.
Anyhow I don’t think QCA broadly defined should be held hostage of debates in “qualitative” methods. QCA is case-oriented (at least in small- and intermediate-N designs), but it is also mathematical (formal logics and set operations) in its operations, etc. (see the numerous contributions in various textbooks and state of the art pieces during the last 10 years).
So: _if_ the core of the matter is the transparency issue (again, I don’t think so), then there should be 3 linked discussions:
- A. What are the core (universal) elements of ‘sound science’ [again, I stress: not limited to what some refer to as ‘qualitative’ science]?
- B. How do these core (universal) elements translate in practical terms for a scientist (NB not only a social scientist!) using QCA?
- C. How to do ‘sound science’ with QCA, more at the technical/applied level (as part of the protocol)?
In my next point below I unfold a tiny bit the third, more focused question.
4/ And finally QCA proper & how I would view the ‘sound science’ (incl. transparency & other things) recommendations
I definitively think we should _not_ begin by listing the technical QCA ‘good practices’ (= only during the QCA ‘analytic moment’) on only one sub-dimension (= only the transparency thing); see above.
My own approach would be very different, and with a much broader/more systematic scope. If I were to start from a blank page, I would write down a series of 3 questions in a logical order [and NB: gladly: we have already produced many answers to these questions over the last 3 decades!]
Question 1: what are the definitional elements of QCA?
I think most of us could agree on a list of 7 to 10 elements – I myself tried to formulate these in a concise way in a piece published in the Swiss Political Science Review (2013); this could easily be crossed/enriched with bits & pieces in reference volumes such as the Rihoux/Ragin & Schneider/Wagemann textbooks.
On that basis, we could also list some ‘fundamental prerequisites’ for a researcher to take on board before (technically) engaging in QCA – I mean: more at the epistemological level. We already have this narrative in various recent pieces.
Question 2: what are the procedural (protocol-related) elements of QCA?
I.e.: if there are 5 main uses of QCA (in a nutshell: 1. typology building, 2. exploring data, 3. testing theories, 4. testing propositions and 5. expanding theories): for each one of these 5 uses: what is the ‘standard & commonly agreed upon protocol’? Possibly with a few alternatives / sub-protocols? For instance if at some stage the researcher opts either for a csQCA or a fsQCA, this directs him/her to two partly different sub-protocols. Depending on the protocol, I guess this could boil down to between ca. 10 to ca. 25 core operations (steps), with iterations, too [by the way, the iterative nature of ‘sound science’ with QCA is for me at least as fundamental as the ‘transparency’ issue; see for instance the discussion in the Rihoux & Lobe chapter in the Byrne & Ragin handbook (2009)].
Question 3: considering these definitional and procedural elements, how to do “sound science” with QCA – throughout the whole research cycle and not only during the ‘analytic moment’?
I would see this as a sort of matrix with, as lines, a quite detailed and ordered list of ‘typical research situations’ in which QCA comes into play at some stage. I guess this could boil down to around 15-25 research situations, depending on how we would aggregate things.
And then as columns I would see first some transversal points, and then the unfolding of the typical sequence of operations (the ‘protocol’, as defined above, i.e. with and ca. 10 to 25 steps depending on the protocol).
And obviously in each one of the cells I would fill in with the respective “sound science” criteria (“quality checks” bullet points) that should be met.
In a very simplified form, this could look like:
- Columns: Research situations // Transversal points/ preoccupations // Step 1 of protocol // Step 2 of protocol /// etc (…)
- and then the lines: for instance:
(…)
Situation 13: csQCA for theory-testing in smaller-N design
(…)
For sure, concrete good practices of ‘transparency’ could find their place in many of these cells – but also some other as important good practices for ‘sound science with QCA’ [perhaps we could agree on 5-6 core criteria that would need to be met in each cell, in fact – and transparency should probably be one of the 5-6 criteria]. And here I have no problem with some of the core points highlighted by Carsten & the contributors to this discussion thread.
For instance: sure: calibration/threshold-setting is, for instance, a core, focal point. NB for this point as well as the others, I think we should always stress that “there are different [technical] good ways to do it” – I mean: keep things pluralistic. For instance: there are at least 4-5 meaningful ways to approach calibration (it’s not only about direct v/s indirect), it depends on the purpose, on the topic, on the theory, on the researcher’s own position, on the nature of the ‘raw’ data [well, there is never really ‘raw’ data…], etc.
And once we have a matrix of this sort [NB I am convinced that we could quite easily find an agreement about at least 90% of the content] it should be made accessible in a readable form (TBD; there are different technical options); COMPASSS would be the obvious place.
By the way, this brings me to another important point/preoccupation of mine: in the next few months & years, we should definitively do this job of clarifying what is ‘sound science with QCA’ (in a way much of our collective discussions over the last few years, in Zurich & other places, have centered precisely on this), but the agenda should not be orientated/guided by some other agendas (I mean: the DA-RT one); we should pursue our own agenda!
OK, I am aware that I haven’t followed Carsten’s injunctions & proposed structure, but I thought I’d be …transparent in expressing my broader perspective .
.
Best,
Benoît
As much as I appreciate the effort and potential interest to have a collective discussion on “research transparency” (this is a preoccupation I think we should all have as researchers, regardless of the discipline and methodological toolbox), I must say that I am a bit reluctant to engage directly in a narrow/technical discussion on the QCA ‘analytical moment’ as is suggested by Carsten. The fundamental reason is that there are – I think – much broader issues at stake, not only in methodological terms but also in ‘political’ terms. So: after having read the discussion thread above, and after having quickly consulted a few contributions around the whole DA-RT thing (impressive how much time and energy has been consumed thus far in this whole enterprise!), I feel the need to first provide a (much) broader picture, with attached notes of caution. I think we should never engage in any ‘technical’ discussion without prior consideration of broader issues at stake. So I will structure my thoughts in 4 points:
1/ the broader ‘political’ picture
2/ the broader scientific picture: why ‘transparency’ in priority? Why not other research qualities?
3/ broader than QCA: the so-called ‘qualitative’ territory (and why I object to that label)
4/ and finally QCA proper & how I would view the ‘transparency _and_ other qualities’ recommendations
NB what follows below is a bit short/blunt & would probably deserve more nuances, elaboration etc., but… I simply have no time right now to write more & I’d like to post my comments before the late 2016 deadline.
1/ The broader ‘political’ picture
Having observed the evolution of debates around political science / social science methods over the last 20 years or so, I am clearly a skeptic (NB: I did not write ‘opponent’) of the whole DA-RT initiative.
To put it short, my simple/quick ‘political’ reading of the whole context that has led to this initiative is the fact that political science (well, social sciences more broadly) are being questioned in terms of their ‘scientificity’ (two keywords in the DA-RT framing docs: “credibility” and “legitimacy”), specifically in the U.S., and vis-à-vis presumably ‘real’ sciences, e.g. experimental & natural sciences, and closer to them some more ‘scientific’(?) disciplines such as economics. Hence the need to demonstrate, somewhat defensively, that indeed there is a ‘science of politics’ – in very concrete terms in order to keep some legitimacy _and_ funding, academic positions and the like. And even more so on the ‘qualitative’ side of political science, which is fighting to gain some scientific legitimacy vis-à-vis the ‘quantitative’ mainstream, and which has precisely created the APSA’s Organized Section for Qualitative and Multi-Method Research (QMMR). I see the whole QTD initiative (launched by that QMMR Section) as a logical continuation in those (mainly U.S.) strategic moves.
I dislike this context, and in fact as seen from Europe I feel quite remote from it. But indeed the broader situation is that social sciences (sociology even more so than political science, I’d say) are seriously in trouble in the ‘global scientific competition’ – and this goes way beyond issues of methods and transparency.
And one reason I really dislike this context is that, hence, only a small segment of sciences (social sciences narrowly defined) sort of feels compelled to engage in that sort of self-justification (OK, this is a negative framing – in favorable terms, one could also argue that this is ‘consolidation’). The end result could prove to be: creating further ‘noise’ (masses of at least partly contradictory or complex positions), thereby further weakening political science/social sciences in the ‘global race’.
2/ The broader scientific picture: why ‘transparency’ in priority? Why not other research qualities?
Here I very much agree with Peter Hall’s points, as he discusses in a recent – and very pondered -- contribution of his in the Comparative Methods Newsletter (Vol. 26, issue 1, 2016, pp. 28-31): “what social scientists should value most highly is not transparency, but the integrity of research, understood as research that reflects an honest and systematic search for truths about society, the economy, or politics. In its various dimensions, transparency is a means toward that end. But it is only one of several such means (…)” (p. 28).
I think the more useful discussion we should have should not revolve solely around “transparency”, but rather on: “what is good [social] science?” or “what is sound [social] scientific work”?
According to me, “sound scientific work” comprises at least three main dimensions – and these are (or should be) universal, I mean across all sciences:
• Formulate a clear ontological/epistemological position (there are many valid positions, but they should be formulated) [NB: in many ‘hard sciences’ publications, this is missing!]
• Develop and implement a sound protocol (i.e. practical operations) – in here there are multiple sub-dimensions, and transparency is only one out of certainly 5 or 6 core sub-dimensions that are at least as important. One other point is, for instance: the adequacy of the protocol to the object(s) and research question(s) at hand. This point, for me, is more fundamental than “transparency” (transparency is already one level down, more at the technical/practical level)
• Keep a reflexive view as ‘scientific crafts(wo)man” – this should be true in all sciences. Nothing should ever be seen as obvious, as ‘definite truth’, as ‘the sole & best protocol’, etc. [again, in many ‘hard sciences’ publications, this is seldom question done]
So: “transparency”, for me, is only one sub-point in a much broader set of three transversal points, and I feel it extremely limitative to be constrained to limit oneself to that sub-point.
3/ Broader than QCA: the so-called ‘qualitative’ territory (and why I object to that label)
The more I do research, the less I find the ‘quantitative’ and ‘qualitative’ labels appropriate. Most researchers who conduct an in-depth case study (allegedly an ideal-type of “qualitative” research) frequently use numbers, statistics, descriptive at the very least. And most scholars who engage in survey research and produce numerically coded ‘data sets’ (matrix-type data) in fact are tapping and labelling ‘qualitative’ variations through the concepts they use.
Anyhow I don’t think QCA broadly defined should be held hostage of debates in “qualitative” methods. QCA is case-oriented (at least in small- and intermediate-N designs), but it is also mathematical (formal logics and set operations) in its operations, etc. (see the numerous contributions in various textbooks and state of the art pieces during the last 10 years).
So: _if_ the core of the matter is the transparency issue (again, I don’t think so), then there should be 3 linked discussions:
- A. What are the core (universal) elements of ‘sound science’ [again, I stress: not limited to what some refer to as ‘qualitative’ science]?
- B. How do these core (universal) elements translate in practical terms for a scientist (NB not only a social scientist!) using QCA?
- C. How to do ‘sound science’ with QCA, more at the technical/applied level (as part of the protocol)?
In my next point below I unfold a tiny bit the third, more focused question.
4/ And finally QCA proper & how I would view the ‘sound science’ (incl. transparency & other things) recommendations
I definitively think we should _not_ begin by listing the technical QCA ‘good practices’ (= only during the QCA ‘analytic moment’) on only one sub-dimension (= only the transparency thing); see above.
My own approach would be very different, and with a much broader/more systematic scope. If I were to start from a blank page, I would write down a series of 3 questions in a logical order [and NB: gladly: we have already produced many answers to these questions over the last 3 decades!]
Question 1: what are the definitional elements of QCA?
I think most of us could agree on a list of 7 to 10 elements – I myself tried to formulate these in a concise way in a piece published in the Swiss Political Science Review (2013); this could easily be crossed/enriched with bits & pieces in reference volumes such as the Rihoux/Ragin & Schneider/Wagemann textbooks.
On that basis, we could also list some ‘fundamental prerequisites’ for a researcher to take on board before (technically) engaging in QCA – I mean: more at the epistemological level. We already have this narrative in various recent pieces.
Question 2: what are the procedural (protocol-related) elements of QCA?
I.e.: if there are 5 main uses of QCA (in a nutshell: 1. typology building, 2. exploring data, 3. testing theories, 4. testing propositions and 5. expanding theories): for each one of these 5 uses: what is the ‘standard & commonly agreed upon protocol’? Possibly with a few alternatives / sub-protocols? For instance if at some stage the researcher opts either for a csQCA or a fsQCA, this directs him/her to two partly different sub-protocols. Depending on the protocol, I guess this could boil down to between ca. 10 to ca. 25 core operations (steps), with iterations, too [by the way, the iterative nature of ‘sound science’ with QCA is for me at least as fundamental as the ‘transparency’ issue; see for instance the discussion in the Rihoux & Lobe chapter in the Byrne & Ragin handbook (2009)].
Question 3: considering these definitional and procedural elements, how to do “sound science” with QCA – throughout the whole research cycle and not only during the ‘analytic moment’?
I would see this as a sort of matrix with, as lines, a quite detailed and ordered list of ‘typical research situations’ in which QCA comes into play at some stage. I guess this could boil down to around 15-25 research situations, depending on how we would aggregate things.
And then as columns I would see first some transversal points, and then the unfolding of the typical sequence of operations (the ‘protocol’, as defined above, i.e. with and ca. 10 to 25 steps depending on the protocol).
And obviously in each one of the cells I would fill in with the respective “sound science” criteria (“quality checks” bullet points) that should be met.
In a very simplified form, this could look like:
- Columns: Research situations // Transversal points/ preoccupations // Step 1 of protocol // Step 2 of protocol /// etc (…)
- and then the lines: for instance:
(…)
Situation 13: csQCA for theory-testing in smaller-N design
(…)
For sure, concrete good practices of ‘transparency’ could find their place in many of these cells – but also some other as important good practices for ‘sound science with QCA’ [perhaps we could agree on 5-6 core criteria that would need to be met in each cell, in fact – and transparency should probably be one of the 5-6 criteria]. And here I have no problem with some of the core points highlighted by Carsten & the contributors to this discussion thread.
For instance: sure: calibration/threshold-setting is, for instance, a core, focal point. NB for this point as well as the others, I think we should always stress that “there are different [technical] good ways to do it” – I mean: keep things pluralistic. For instance: there are at least 4-5 meaningful ways to approach calibration (it’s not only about direct v/s indirect), it depends on the purpose, on the topic, on the theory, on the researcher’s own position, on the nature of the ‘raw’ data [well, there is never really ‘raw’ data…], etc.
And once we have a matrix of this sort [NB I am convinced that we could quite easily find an agreement about at least 90% of the content] it should be made accessible in a readable form (TBD; there are different technical options); COMPASSS would be the obvious place.
By the way, this brings me to another important point/preoccupation of mine: in the next few months & years, we should definitively do this job of clarifying what is ‘sound science with QCA’ (in a way much of our collective discussions over the last few years, in Zurich & other places, have centered precisely on this), but the agenda should not be orientated/guided by some other agendas (I mean: the DA-RT one); we should pursue our own agenda!
OK, I am aware that I haven’t followed Carsten’s injunctions & proposed structure, but I thought I’d be …transparent in expressing my broader perspective
Best,
Benoît
Post Reply